Snowflakeの自然言語分析(Text to SQL)の精度を安定させるビジネスメタデータ設計とは
- 公開日:

Snowflake上のデータに対して、
「今月の売上が落ちている要因は?」
「商品カテゴリ別の粗利率を前年同月比で比較して」
と自然言語で質問し、即座に正確な結果を得る——。
Cortex Analystをはじめとする自然言語分析機能の進化により、SnowflakeはデータクラウドからAI DATA CLOUD(AI活用基盤)へと進化しています。

しかし実際の現場では、
- 精度が安定しない
- 定義の解釈がずれる
- IT部門への問い合わせが減らない
といった課題も多く聞かれます。
なぜSnowflakeの自然言語分析は「デモでは動くが業務で定着しない」のでしょうか。本ブログでは、その本質的な原因と解決の方向性を解説します。
Index
自然言語分析(Text to SQL)が直面する2つの壁
Snowflake上のSQL/BI運用のボトルネック
Snowflakeは強力なSQL実行基盤を持ちます。しかし、
- ビジネスユーザーが直接SQLを書くのは難しい
- BIダッシュボードの探索には習熟が必要
- 新しい分析要求は都度データ部門に依頼が必要
という構造は、多くの企業で依然として存在します。
自然言語分析(Text to SQL)*は、この「ラストワンマイル」を解消する技術です。しかし、単にインターフェースを自然言語に変えるだけでは本質的な解決にはなりません。
*自然言語分析(Text to SQL):自然言語をSQLに変換し、データベースから必要なデータを取得する技術
Snowflake上の「暗黙知」がAIの精度を不安定に…
Snowflakeには正確なデータが蓄積されています。しかし、
- 売上は税抜か税込か
- 粗利はどの原価を含むのか
- 部門別集計の粒度は?
といった「ビジネス上の意味」が構造化されていない場合、AIは推測でSQLを生成します。
結果として、
- 正しいSQLだが意図と違う結果
- 同じ質問でも日によって解釈が揺れる
- ハルシネーション*的な回答
が発生します。
Snowflakeの問題ではありません。
「意味の共有設計」が不足していることが原因です。
*ハルシネーション:生成AIが事実に基づかない情報を生成してしまう現象のこと
自然言語分析の精度はCortex Analystだけでは決まらない
Cortex Analystは、あらかじめYAML*で定義されたセマンティックモデルを参照し、自然言語をSQLに変換します。
*YAML:半構造化データのフォーマットの一つで、人間がデータを簡潔かつ理解しやすく表現するように設計された、構造化データをテキスト形式で表現する形式
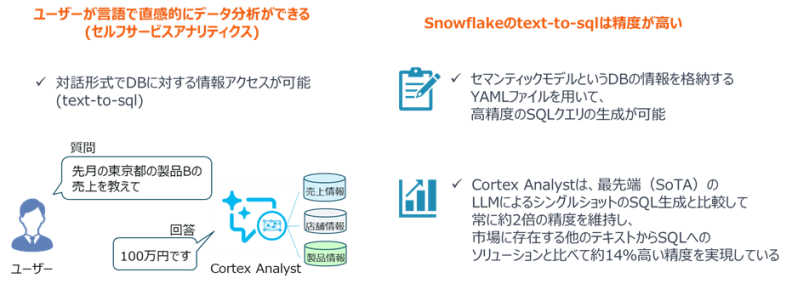
しかし重要なのは、
- どの指標を
- どの定義で
- どの粒度で
- どの権限で
扱うのかというビジネスメタデータ設計です。
LLMの性能を上げることよりも、Snowflake内のセマンティックレイヤーをどう設計するかの方が、業務精度には大きく影響します。
データカタログとビジネスメタデータの重要性
データカタログとは、メタデータを「管理・検索するための仕組み」です。データカタログを導入することで企業にメタデータ管理・ガバナンスがもたらされます。

ここに格納されるべきなのは、単なるテーブル情報ではありません。
- 指標定義
- 計算式
- 同義語
- データリネージ
- アクセス制御
これらを構造化し、Cortex Analystと連携することで、
- 正しい定義に基づくSQL生成
- セキュアな回答制御
- 解釈の一貫性
が実現できます。ただし、ここで終わってはいけません。
*データカタログについてはこちらでも詳しくご紹介しております。あわせてご覧ください。
自然言語分析を「育てる」運用ループ設計
業務で定着する自然言語分析には、以下のループが必要です。
- 利用ログの収集
SnowflakeのQuery HistoryやAccess Historyから、
・どのクエリが多用されているか
・どの分析が頻出か
を把握します。 - 頻出分析のメタデータ化
頻繁に使われる指標・集計パターンをビジネスメタデータとして整理し、Horizon*へ格納します。
*Horizon: Snowflakeが提供するユニバーサルAIカタログ機能https://www.snowflake.com/ja/product/features/horizon/ - セマンティックモデルへの反映
YAMLモデルを更新し、Cortex Analystが理解できる形に整備します。 - 精度検証と改善
実際の質問ログを用いて回答精度を検証し、継続的に改善します。
このループを回すことで、Snowflake上の自然言語分析は“使うほど賢くなる”状態に進化します。
精度は静的なものではなく、運用で育てるものなのです。
自然言語分析導入で見落とされがちなポイント
多くのプロジェクトでは、
- PoCで動いた
- デモで成功した
という段階で安心してしまいます。しかし本番環境では、
- 新しい指標の追加
- 組織変更
- データモデル変更
- アクセス権限変更
が日常的に発生します。
これらに追従できない設計では、精度は徐々に劣化します。
重要なのは、Snowflake基盤+AI機能+メタデータ運用を一体設計することです。
まとめ
Snowflakeの自然言語分析(Text to SQL)は、強力な可能性を持っています。しかし成功の鍵は、
- Cortex Analystの活用
- データカタログによるメタデータ管理
- セマンティックモデル設計
- 継続的な運用改善ループ
にあります。単なるチャットインターフェース導入では、業務に耐える「正しさ」は担保できません。
これからのSnowflake活用は、既存のデータ基盤を“すぐ使えるAI”に変え、さらに“育て続けるAI”へ進化させる設計思想が求められます。
貴社のSnowflake環境では、
- ビジネスメタデータは体系化されていますか?
- Query Historyは精度改善に活用されていますか?
- セマンティックモデルは継続的に更新されていますか?
もし明確に答えられない場合、
自然言語分析のポテンシャルはまだ十分に引き出されていないかもしれません。
Snowflakeを“AI活用基盤”として真に機能させるために、
いま一度、メタデータと運用設計を見直してみてはいかがでしょうか。
弊社は、データの可視化や従来の分析に留まらないAIを用いたより高度なデータ分析基盤の構築や活用をご支援しております。
Snowflakeを用いたデータ活用でお悩みの際は、是非弊社までお声掛けください。
本記事は、2026年3月1日時点の情報をもとに作成しています。製品・サービスに関する詳しいお問い合わせは、弊社Webサイトからお問い合わせください。
https://data-management.dentsusoken.com/snowflake/inquiry/
本サイトのブログ記事に加え、Snowflakeを中心としたデータエンジニアリング関連の技術的な情報を掲載したテックブログもWeb公開しております。
是非、こちらのテックブログもご覧ください。
https://zenn.dev/p/datatechblog